Tutorial Membuat Interpreter dan Compiler (bagian 8)
part 1 part 2 part 3 part 4 part 5 part 6 part 7 part 8 part 9
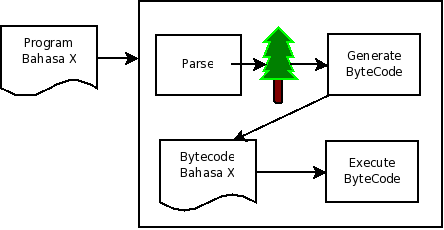
Dalam bagian ini, saya akan memperkenalkan eksekusi berbasis bytecode. Tutorial kali ini tidak mengandung kode program yang dapat dijalankan.
Cara eksekusi yang telah dijelaskan dalam bagian-bagian sebelumnya dilakukan dengan tree walking. Artinya kita mengunjungi setiap node pohon sambil mengeksekusi node tersebut. Cara eksekusi lain yang lebih umum digunakan saat ini adalah dengan pendekatan byte code. Ketika mengunjungi tree, kita tidak mengeksekusi, tapi menghasilkan bytecode.
Bytecode yang dihasilkan ketika mengunjungi pohon bisa dituliskan ke file (misalnya dalam kasus bahasa Java, file .class adalah bytecode), atau disimpan di memori (misalnya dalam kasus PHP byte code disimpan di memori). Setelah bytecode dihasilkan, langkah selanjutnya adalah eksekusi oleh virtual machine. Hasil bytecode kemudian dijalankan oleh sebuah virtual machine.
Wikipedia memiliki artikel mengenai Bytecode
Bytecode adalah instruksi sederhana yang dapat dieksekusi dengan efisien. Kita bisa menggunakan bytecode yang sudah ada (misalnya bytecode Java atau Parrot). Kita juga bisa membuat bytecode sendiri dengan mendefinisikan suatu instruction set (himpunan instruksi) yang cocok untuk kebutuhan kita.
Mungkin Anda akan bertanya: lalu apa sebuah compiler yangmenghasilkan kode assembly dalam dengan sebuah interpreter yang memakai pendekatan bytecode? Keduanya memang sangat mirip, dan perbedaannya tipis.
- Bytecode untuk suatu interpreter merupakan rancangan pembuat virtual machine. Umumnya byte code ini sederhana, dan sesuai dengan domain interpreter. Misalnya sebuah interpreter yang hanya menangani integer, tidak perlu memiliki instruksi sama sekali yang berhubungan dengan string.
- Machine/native code mengikuti bahasa mesin yang dirancang oleh pembuat CPU. Set instruksi yang ada untuk suatu CPU sangat generik, dan rumit. Menghasilkan kode yang efisien untuk suatu CPU merupakan hal yang rumit.
Perlu ditegaskan bahwa dalam praktik, perbedaan tersebut sangat tipis karena sebuah bytecode bisa juga dikompilasi menjadi machine code (contohnya kode .class bisa dikompilasi menjadi native code dengan compiler gcj).
Kelebihan dan kekurangan
Apa kelebihan pendekatan byte code dibanding eksekusi langsung? kelebihan utama adalah eksekusi bisa lebih cepat, karena source code dalam bentuk teks tidak perlu diparse berulang kali. Jika bytecode disimpan dalam file, maka kita bisa menjalankan file tersebut cukup dengan memporting bagian virtual machine, tidak perlu keseluruhan interpreter. Apa kelemahan pendekatan bytecode? kita harus bekerja ekstra untuk menghasilkan bytecode dan membuat virtual machine.
Dibandingkan dengan compiler yang menghasilkan kode native untuk sebuah CPU tertentu, interpreter bytecode lebih baik karena lebih portabel. Tapi kelemahannya adalah: eksekusi bytecode lebih lambat dibandingkan dengan kode native CPU.
Membuat atau memakai yang sudah ada?
Secara singkat jawaban yang bisa saya berikan adalah: pakailah bytecode yang sudah ada. Hanya dalam kasus sangat khusus kita perlu mendefinisikan bytecode kita sendiri. Beberapa bytecode yang sudah ada populer yang sudah ada:
- Java Bytecode, dipakai oleh Java, Groovy, Clojure, dll
- Common Intermediate Language (CIL), yang dulunya dikenal sebagai Microsoft Intermediate language (MSIL) dipakai bahasa-bahasa .NET
- Parrot Assembly Language (PASM), yang dipakai oleh Perl 6
Sudah banyak virtual machine dan tools yang tersedia untuk aneka macam bytecode tersebut. Misalnya, untuk java bytecode sudah ada aneka macam virtual machine (silakan lihat daftarnya di List of Java virtual machines), sudah ada tools untuk konstruksi, verifikasi, dan bahkan dekompilasi. Spesifikasi bytecode yang sudah ada biasanya sudah lengkap, dan sudah teruji, baik dari sisi performansi maupun sekuritinya.
Untuk keperluan tutorial, saya akan mencoba memperkenalkan sebuah bytecode baru yang sederhana. Memahami bytecode sederhana ini dapat membantu Anda memahami bytecode lain yang lebih kompleks (misalnya aneka bytecode populer yang sudah saya sebutkan). Saya namakan bytecode ini Epsilon.
Mendefinisikan set instruksi
Sebenarnya tidak ada batasan apapun untuk merancang instruksi apa yang akan ada di sebuah bytecode. Kita bisa membuat instruksi yang sangat sederhana, ataupun yang sangat rumit. Kita bisa membuat eksekusi berbasis stack, atau berbasis register (atau gabungan keduanya). Meski ada banyak kebebasan, namun instruksi sebaiknya sederhana, akan lebih baik lagi jika setiap instruksi bisa dipetakan dengan mudah ke aneka bahasa mesin (native code).
Sebagian besar virtual machine berbasis stack, karena lebih mudah diimplementasikan. Sebagian kecil (misalnya Parrot) berbasis register. Berbasis stack artinya stack digunakan sebagai tempat sementara untuk penyimpanan ketika eksekusi dilakukan, sedangkan berbasis register artinya register digunakan sebagai tempat penyimpanan sementara ketika eksekusi dilakukan.
Misalkan kita ingin mengeksekusi A * 7 + 5, mari kita lihat contoh eksekusi berbasis stack, lalu berbasis register.
Dalam eksekusi berbasis stack, pasti ada instruksi untuk memasukkan nilai ke stack, umumnya nama instruksinya push, lalu akan ada instruksi yang beroperasi terhadap nilai di stack, misalnya instruksi add untuk menambah dua nilai di stack, atau mul untuk mengalikan dua nilai di stack. Instruksi 4 + 5 bisa dilakukan seperti ini:
PUSH A
PUSH 7
MUL
PUSH 5
ADD
Ingat, Anda bisa memberi nama apapun untuk instruksi, misalnya
DORONG,ANGKUT,TAMBAH, dsb. Nama yang dipakai di sini hanyalah nama yang umum digunakan.
Instruksi push A akan menaruh nilai A di stack, instruksi push 7 akan menaruh 7 di stack, instruksi mul akan mengambil dua nilai dari stack, mengalikannya, lalu menaruh hasilnya di stack. Instruksi push 5 akan menaruh nilai 5 di stack, dan instruksi add akan menjumlahkan hasilnya dan menaruh hasilnya di stack.
Saya berikan contoh dengan nilai A = 10.
PUSH A --> ISI STACK [10 ]
PUSH 7 --> ISI STACK [10 7]
MUL --> ISI STACK [70]
PUSH 5 --> ISI STACK [70 5]
ADD --> ISI STACK [75]
Mari kita bandingkan dengan eksekusi berbasis register. Misalkan kita memiliki n buah register saja, yang bernama R1..Rn. Dalam eksekusi berbasis register, kita akan punya instruksi untuk memberi nilai ke suatu register, biasanya nama instruksi ini mov. Lalu kita akan memiliki seperangkat instruksi yang beroperasi terhadap register, misalnya add r1, r2, atau add r1, 5. Mari kita coba contoh sebelumnya dalam bentuk eksekusi berbasis register.
MOV R1, A
MUL R1, 7
ADD R1, 5
Biasanya bytecode berbasis register akan lebih singkat. Namun kita akan memiliki masalah dalam alokasi register (jika jumlah register terbatas).
Mari kita bahas instruksi-instruksi tersebut. Instruksi mov r1,a akan mengisikan register r1 dengan nilai variabel A. Instruksi mul r1, 7 akan mengalikan isi register r1 dengan 7 dan menaruh hasilnya di r1. Instruksi add r1, 5, akan menambahkan r1 dengan 5 dan menyimpan hasilnya di r1.
Saya berikan contoh dengan nilai A = 10.
MOV R1, A ---> R1 = 10
MUL R1, 7 ---> R1 = 70
ADD R1, 5 ---> R1 = 75
Encoding dalam bentuk biner
Instruksi-instruksi yang telah saya bahas sifatnya tekstual mul, add r1,5, dsb. Agar efisien bytecode biasanya tidak dinyatakan dalam bentuk teks, tapi dalam bentuk biner/numerik. Misalnya kita bisa memberi nomor untuk push untuk variabel dengan nilai 1, push untuk angka dengan nilai 2, mul dengan nilai 3, dan add dengan nilai 4.
Instruksi ini:
PUSH A
PUSH 7
MUL
PUSH 5
ADD
Bisa kita ubah menjadi:
PUSH A | 1 A
PUSH 7 | 2 7
MUL | 3
PUSH 5 | 2 5
ADD | 4
Dan sebaiknya kita juga tidak menggunakan nama, tapi memberi nomor identitas juga untuk variabel, misalnya variabel pertama diberi nomor 1, variabel kedua diberi nilai 2, dst. Sehingga menjadi:
PUSH A | 1 1
PUSH 7 | 2 7
MUL | 3
PUSH 5 | 2 5
ADD | 4
Tentunya angka-angka tersebut tidak perlu disusun menurun seperti itu, kita bisa menyusunnya horizontal sebagai angka-angka atau byte-byte:
1 1 2 7 3 2 5 4
Angka-angka itulah yang merupakan representasi bytecode kita. Eksekusi bisa dilakukan dengan kode semacam ini (ini hanya potongan kode dalam Java, bukan bagian dari program utuh):
int execute(int bytecode[])
{
int ip = 0; /*instruction pointer*/
Stack<Integer> stack = new Stack<Integer>();
while (ip<bytecode.length) {
switch (bytecode[ip]) {
case 1: /*push variable*/
ip++;
int var = bytecode[ip];
ip++;
stack.push(getVariableValue(var));
break;
case 2: /*push value*/
ip++;
int value = bytecode[ip];
ip++;
stack.push(value);
break;
case 3: /*mul*/
int v1 = stack.pop();
int v2 = stack.pop();
stack.push(v1*v2);
ip++;
break;
case 4: /*mul*/
int v1 = stack.pop();
int v2 = stack.pop();
stack.push(v1+v2);
ip++;
break;
}
}
return stack.pop();
}
Seperti yang Anda lihat, eksekusi bytecode cukup sederhana. Kita mulai dari instruksi pertama, dan ip (instruction pointer) dimajukan sesuai instruksi yang ditemui. Ada instruksi yang memajukan ip sebanyak 1 (add dan mul), dan ada yang memajukan sebanyak 2 (mul). Encoding yang panjangnya bervariasi dinamakan variable length encoding. Agar lebih seragam (dan lebih mudah eksekusinya), kita bisa memakai fixed length encoding. Kelemahannya adalah fixed length encoding akan butuh penyimpanan yang lebih besar.
Contoh memakai fixed length encoding adalah dengan selalu menambahkan 0 jika instruksi hanya 1 angka. Untuk instruksi ini:
PUSH A | 1 A
PUSH 7 | 2 7
MUL | 3
PUSH 5 | 2 5
ADD | 4
Kita bisa menambahkan 0 untuk mul dan add menjadi:
PUSH A | 1 A
PUSH 7 | 2 7
MUL | 3 0
PUSH 5 | 2 5
ADD | 4 0
Eksekusi menjadi lebih sederhana:
int execute(int bytecode[])
{
int ip = 0; /*instruction pointer*/
Stack<Integer> stack = new Stack<Integer>();
while (ip<bytecode.length) {
switch (bytecode[ip]) {
case 1: /*push variable*/
int var = bytecode[ip+1];
stack.push(getVariableValue(var));
break;
case 2: /*push value*/
int value = bytecode[ip+1];
stack.push(value);
break;
case 3: /*mul*/
int v1 = stack.pop();
int v2 = stack.pop();
stack.push(v1*v2);
break;
case 4: /*mul*/
int v1 = stack.pop();
int v2 = stack.pop();
stack.push(v1+v2);
break;
}
ip += 2;
}
return stack.pop();
}
Kondisi dan Loop
Setelah dapat mengeksekusi ekspresi, hal yang ingin kita lakukan berikutnya adalah mengevaluasi kondisi dan melakukan loop. Contohnya kita ingin mengeksekusi ini (Anggap saja variabel a dan b sudah terdefinisi):
if (a<10) {
b = b + 50;
} else {
b = b * 2;
}
Kita perlu instruksi komparasi untuk bytecode kita, misalnya cmpgt (compare greater) untuk komparasi lebih besar dari, dan cmplt (compare less than) untuk lebih besar dari atau sama dengan (dsb, kita perlu instruksi terpisah untuk <, >, <=, >=, ==). Setelah instruksi komparasi ini perlu melakukan aksi, yaitu melompat ke label tertentu.
Untuk melompat kita butuh instruksi JUMPFALSE yang akan melompat jika isi top of stack isinya 0. Kita juga perlu instruksi untuk melompat ke label tertentu tanpa kondisi (unconditional jump), biasanya namanya adalah jump. Perhatikan contoh instruksi ini sebagai terjemahan instruksi di atas:
PUSH A
PUSH 10
CMPLT
JUMPFALSE ELSEPART
PUSH B
PUSH 50
ADD
POP B
JUMP DONE
ELSEPART:
PUSH B
PUSH 2
MUL
POP B
DONE:
Kita juga perlu instruksi baru pop untuk mengambil isi stack dan memasukan nilainya ke sebuah variabel.
Berikut ini contoh eksekusi jika A bernilai 5 dan B bernilai 100:
PUSH A ---> ISI STACK [5]
PUSH 10 ---> ISI STACK [5 10]
CMPLT ---> ISI STACK [1], --> 5 < 10
JUMPFALSE ELSEPART ---> ISI STACK []
PUSH B ---> ISI STACK [100]
PUSH 50 ---> ISI STACK [100 50]
ADD ---> ISI STACK [150]
POP B ---> ISI STACK []
JUMP DONE ---> LOMPAT KE DONE
ELSEPART:
PUSH B
PUSH 2
MUL
POP B
DONE: ---> ISI STACK []
Instruksi cmpge akan membandingkan dua nilai di top of stack, dan akan melompat jika nilai pertama lebih besar atau sama dengan nilai kedua. Dalam kasus A bernilai 5, eksekusi akan terus. Instruksi jump akan melompat ke sebuah label. Setelah mengeksekusi bagian if, kita tidak ingin bagian else juga dieksekusi, jadi kita melompat melewati elsepart ke bagian done.
Berikut ini contoh eksekusi jika A bernilai 15 dan B bernilai 100:
PUSH A ---> ISI STACK [5]
PUSH 10 ---> ISI STACK [5 10]
CMPLT ---> ISI STACK [0], --> 15 > 10
JUMPFALSE ELSEPART ---> ISI STACK [] --> ELSEPART
PUSH B
PUSH 50
ADD
POP B
JUMP DONE
ELSEPART:
PUSH B ---> ISI STACK [100]
PUSH 2 ---> ISI STACK [100 2]
MUL ---> ISI STACK [200]
POP B ---> ISI STACK []
DONE: ---> ISI STACK []
Dalam kasus A bernilai 15, eksekusi akan lanjut ke bagian elsepart.
Instruksi komparasi dan jump dipakai baik pada bytecode berbasis register ataupun stack
Sekarang kita bisa memberi nilai pada instruksi CMPLT (misalnya 5), JUMP (misalnya 6), JUMPFALSE 7 dan POP (misalnya 8). Bytecode menjadi seperti ini (variabel A adalah variabel ke 1 dan B adalah variabel no 2). Dari contoh sebelumnya push variabel = 1, push angka = 2, mul = 3, dan add = 4.
PUSH A | 1 1
PUSH 10 | 2 10
CMPLT | 5 0
JUMPFALSE ELSEPART | 7 ELSEPART
PUSH B | 1 2
PUSH 50 | 2 50
ADD | 4 0
POP | 8 1
JUMP DONE | 6 DONE
ELSEPART:
PUSH B | 1 2
PUSH 2 | 2 2
MUL | 3 0
POP | 8 1
DONE:
Anda perhatikan ada yang aneh? masih memakai label ELSEPART dan DONE, padahal itu harus menjadi angka. Mari kita beri nomor byte di setiap baris. Karena sebelumnya sudah diputuskan untuk menggunakan fixed byte encoding, jumlah byte di setiap baris selalu sama, yaitu 2:
catatan: penomoran alamat ini mengasumsikan 1 instruksi adalah 1 byte, dalam kenyataannya, jika ingin menyimpan > 256 nilai, kita perlu tipe data yang lebih besar
00 PUSH A | 1 1
02 PUSH 10 | 2 10
04 CMPLT | 5 0
06 JUMPFALSE ELSEPART | 7 ELSEPART
08 PUSH B | 1 2
10 PUSH 50 | 2 50
12 ADD | 4 0
14 POP | 8 1
16 JUMP DONE | 6 DONE
18 ELSEPART: PUSH B | 1 2
20 PUSH 2 | 2 2
22 MUL | 3 0
24 POP | 8 1
26 DONE:
Sekarang kita bisa mengganti label ELSEPART dan DONE dengan angka, yaitu nomor bytenya
00 PUSH A | 1 1
02 PUSH 10 | 2 10
04 CMPLT | 5 0
06 JUMPFALSE ELSEPART | 7 18
08 PUSH B | 1 2
10 PUSH 50 | 2 50
12 ADD | 4 0
14 POP | 8 1
16 JUMP DONE | 6 26
18 ELSEPART: PUSH B | 1 2
20 PUSH 2 | 2 2
22 MUL | 3 0
24 POP | 8 1
26 DONE:
Sekarang representasi bytecodenya menjadi:
1 1 2 10 5 0 7 18 1 2 2 50 4 0 8 1 6 26 1 2 2 2 3 0 8 1
Eksekusi bytecode juga tetap sederhana:
void execute(int bytecode[])
{
int ip = 0; /*instruction pointer*/
Stack<Integer> stack = new Stack<Integer>();
while (ip<bytecode.length) {
switch (bytecode[ip]) {
case 1: /*push variable*/
int var = bytecode[ip+1];
stack.push(getVariableValue(var));
break;
case 2: /*push value*/
int value = bytecode[ip+1];
stack.push(value);
break;
case 3: /*mul*/
int v1 = stack.pop();
int v2 = stack.pop();
stack.push(v1*v2);
break;
case 4: /*mul*/
int v1 = stack.pop();
int v2 = stack.pop();
stack.push(v1+v2);
break;
case 5: /*cmplt*/
int v1 = stack.pop();
int v2 = stack.pop();
stack.push(v2<v1?1:0);
break;
case 6: /*jump*/
ip = bytecode[ip+1];
continue; /*JUMP*/
case 7: /*jump false*/
int v1 = stack.pop();
if (v1==0) {
ip = bytecode[ip+1];
}
continue; /*JUMP*/
case 8: /*jump false*/
int v1 = stack.pop();
setVariableValue(bytecode[ip+1], v1);
break;
}
ip += 2;
}
}
Tentunya bagian yang sulit adalah bagian menghasilkan bytecodenya. Namun ini akan dibahas di bagian lain.
Bagaimana dengan Loop? Loop dapat dikonstruksi dengan compare + jump. Misalnya loop ini:
while (a<10) {
a = a + 1;
}
Dapat direpresentasikan seperti ini:
START_WHILE:
PUSH A
PUSH 10
CMPLT
JUMPFALSE DONE
PUSH A
PUSH 1
ADD
POP A
JUMP START_WHILE
DONE:
Dalam contoh tersebut dilakukan perbandingan A dengan 10, jika A > 10, maka kondisi sudah terpenuhi, jadi lompat ke bagian done. Jika belum, instruksi berikutnya akan dieksekusi, sampai kembali melompat ke start_while. Perhatikan: tidak ada perubahan yang diperlukan dalam bagian virtual machine, karena tidak ada instruksi baru!
Semua bentuk loop (while, for, repeat until, dan do while) dapat direpresentasikan menggunakan instruksi perbandingan (compare) dan lompat (jump).
String dan tipe data lain
Instruksi dan bilangan integer bisa disimpan dalam bentuk bilangan, bagaimana dengan string? misalnya, bagaimana merepresentasikan a = "hello"?. Konstanta string biasanya disimpan dalam tempat khusus (biasanya setelah atau sebelum instruksi, tapi tidak ada yang melarang Anda meletakkannya di tengah-tengah). Setiap literal string diberi nomor, dan Anda bisa merefer string bedasarkan nomornya.
Bagaimana dengan tipe data yang lain? tipe floating point bisa direpresentasikan dalam bentuk byte-byte sesuai representasi bit-nya. Misalnya floating point 32 bit bisa di simpan sebagai 4 byte.
Masalah lain adalah: bagaimana berurusan dengan aneka tipe data? Dalam bahasa yang tipenya statik bagian interpreter yang memeriksa apakah konversi perlu dilakukan, lalu menghasilkan instruksi untuk melakukan konversi. Contohnya di bytecode java ada instruksi i2d (ubah integer di top of stack menjadi double). Dalam bahasa yang tipenya dinamik, virtual machine menjadi lebih rumit karena harus melakukan pemeriksan tipe.
Bermain dengan bytecode Java
Anda bisa mengkompilasi sebuah file java menjadi bytecode (file .class), lalu melihat hasil disassembly kelas tersebut menjadi instruksi-instruksi bytecode dengan program javap (disertakan dalam distribusi Java SDK). Sebagai pengingat: bytecode java dijalankan di virtual machine berbasis stack.
class Test {
double add(int a, double b) {
return a +b;
}
}
And perlu mengkompilasi dulu file Java menjadi file .class
javac Test.java
Lalu Anda akan bisa menggunakan javap untuk melihat bytecodenya. Contoh penggunaan javap:
javap -c Test
Hasilnya:
class Test extends java.lang.Object{
Test();
Code:
0: aload_0
1: invokespecial #1; //Method java/lang/Object."<init>":()V
4: return
double add(int, double);
Code:
0: iload_1
1: i2d
2: dload_2
3: dadd
4: dreturn
}
Anda bisa merujuk referensi bytecode yang lengkap di:
http://java.sun.com/docs/books/jvms/second_edition/html/Instructions.doc.html
Saya jelaskan sedikit bytecode untuk method add. Method ini punya 2 parameter, sebuah int dan double.
- Instuksi
iload_1(integer load param 1) akan meload parameter pertama (sebuahint) ke stack. - Instruksi
i2d(int to double) akan mengubah isi top-of-stack menjadidouble. - Instuksi
dload_2(double load param 2) akan meload parameter kedua (sebuahdouble) ke stack. - Instruksi
dadd(double add) akan menambah dua buah double yang ada di stack (ingat, parameterintsudah diubah menjadidoubleolehi2d). - Instruksi terakhir,
dreturn(double return) akan mengambil nilai dari top of stack dan mengembalikan sebuah nilai bertipedoubleke pemanggil method tersebut.
Penutup
Demikianlah tutorial kali ini yang hanya membahas masalah bytecode. Dalam tutorial berikutnya saya akan memberi contoh bagaimana menghasilkan bytecode. Dan berikutnya kita tidak akan menggunakan bytecode kita sendiri, tapi menggunakan bytecode yang sudah ada.
blog comments powered by Disqus
Copyright © 2009-2018 Yohanes Nugroho